TL;DR Is Deep Learning always the best tool for Natural Language Understanding tasks? Not necessarily!
Recently, a paper from Facebook AI Research (FAIR) appeared on arXiv, under the intriguing title Bag of Tricks for Efficient Text Classification [1], promptly catching the NLP community’s attention. Even more intriguingly, FAIR soon followed up with an open source implementation a.k.a. fastText [2]. In this work (essentially a simple modification of the unsupervised Word2Vec algorithm to deal with supervised learning tasks), the authors made a convincing case for the frequent superiority of shallow networks - as opposed to deep ones - for common text understanding tasks such as sentence classification, dispelling the myth that "deeper is always better". Furthermore, this paper is but one example in the recent slew of results casting the "silver bullet" efficacy of complex neural architectures into question for text-related tasks (see some examples here [3], here [4] and here [5]).
Surprised? After all, isn’t Deep Learning a new disruptive force in AI, shown beyond doubt to be clearly superior to prior "shallow" learning approaches? Well, it depends who you ask. Ask a Computer Vision or a Speech Recognition expert, and you’ll get and enthusiastic Yes! In Computer Vision, novel DL architectures (such as VGG, GoogleNet, Inception, etc.) have delivered extremely impressive results on benchmarks such as ImageNet and CIFAR, even defying expectations of some DL champions [6]. In Speech Recognition, commercial heavyweights such as Google and Baidu have longs since switch to DL architectures. It should only be natural to expect, then, to see the same trend in NLP/NLU, shouldn’t it?
On the face of it, yes - in a way. The tide of enthusiasm in Deep Learning has of course spilled over to the NLU community, triggering a massive conversion of both academics and industry practitioners to the newfound DL religion. Impressive results from other fields, helped by the success of the seminal Word2Vec (followed by Glove and the like) were too much to resist. RNN and LSTM have since become mainstream techniques, offered by popular DL libraries such as TensorFlow, Keras, DL4J, etc. Among other big companies, Google has been at the forefront of both open-sourcing DL techniques (with TensorFlow) and adopting DL architectures in production (in the NLU domain, SmartReply is one recent example).
So - you ask - isn’t that enough? Where do I sign up?! Well, dear friend: if you are reading this, chances are, you are not Google and you likely have neither similarly massive amounts of training data nor their virtually unlimited computational resources. For the rest of us, it is important to understand the performance/computation tradeoffs that come with DL - which is what this post is really about. So let us look at some key problems one by one. In this overly high-level post, we will focus on text classification and a bit of language modeling.
Тext Classification
Clearly, text classification is a common task with plenty of applications: search, user intent determination, sentiment analysis, topic modeling (slightly different, but close), sequence labeling (related), etc. For text classification, we typically have 3options:
-
"Good old" classifiers such as Random Forests (RF) or Logistic Regression (LR). In this case, we’ll typically use a Bag of Word (BoW) representation such as TF/IDF.
-
Pros: well understood models, relatively intuititive features you can control, speed.
-
Cons: the features are "semantically blind": we’ll miss any words or synonyms that are not in the training set. Also, to push performance, manual feature engineering may be required.
-
-
Shallow Neural Networks (NNs) such as Facebook’s fastText.
-
Pros: still fast, no feature engineering, possibly inherits Word2Vec’s nice semantic properties (more on that below).
-
Cons: relatively black box (as all NNs are, whether deep or shallow): little intuition or control over the features.
-
Insights: whether deep or shallow, there is one important distinction about NNs. Many traditional classification methods aim to learn a feature space partitioning function (as a means to separate samples of different classes), leaving feature engineering to the application developer. Conversely, NNs actually do more than that: they seek to learn the optimal representation (read: N-dimensional vector encoding of your data points: words, sentences, paragraphs, what have you…) so as to minimize some loss function on the training set. That learned representation is a byproduct that can sometimes be more valuable than the main task! For instance, in Word2Vec, the task is predicting a word based on the words around it (or vice-versa), which admittedly is not a very common problem in reality. However, as a byproduct, we get word vectors with some interesting semantic properties (e.g., analogies such as the famous king - man + woman = queen example) that become handy in text classification and other application.
-
-
Deep neural networks such as RNNs/LSTMs or ConvNets. Let us discuss this option in more detail below.
Recurrent Neural Networks (RNNs) are category of NN-based models designed specifically for sequences of arbitrary length. The basic RNN unit works by injesting and outputting one symbol at a time, where last time step’s output is also a new time step’s input - see the illustration below. In other words, RNN units have memory short-term memory! Which makes particularly attractive tool for modeling text.
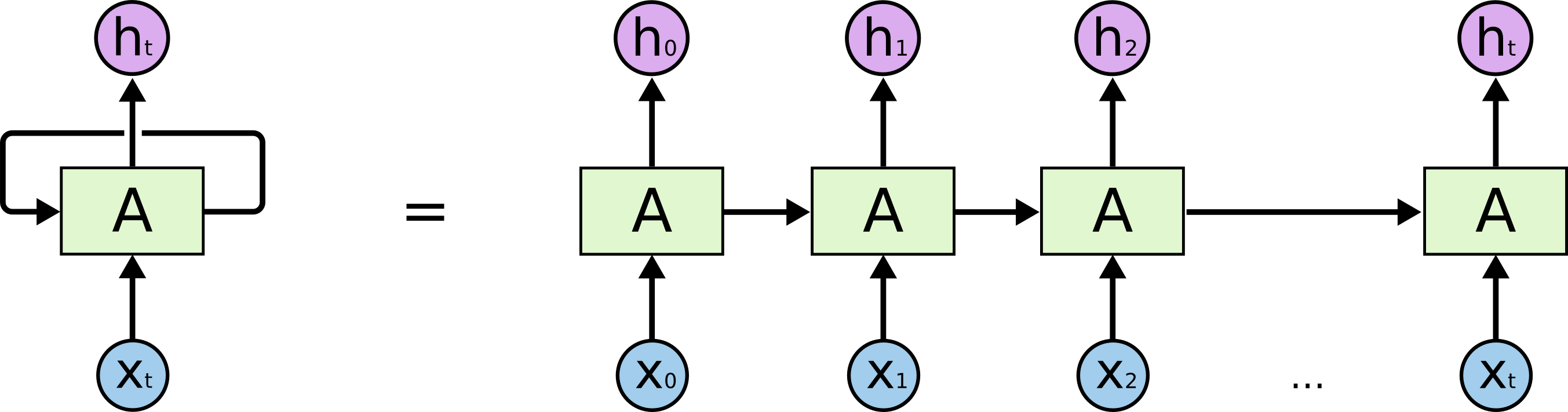
However, in practice, RNNs can be hard to train and for small to medium-sized training datasets, "good old" methods can often deliver similar or even superior performance at a lower computational cost. Even in the Deep Learning category, RNNs have a strong competitor in Convolutional Neural Nets (a.k.a. ConvNets or CNNs) - just as long as your text can be treated as fixed length sequences, making them a suitable approach to represent and classify tweets, text messages, short user reviews, etc. Still, it’s too early to dismiss RNNs and their variants entirely. Where these networks (and particularly their more advanced variant called Long-Short Memory Networks or LSTMs) begin to shine are other NLU tasks that often involve prediction (i.e., generative in nature) rather than "just" classification, a fundamentally discriminative task. So, let us look beyond classification.
Language modeling
Language modeling is a fundamental NLP task, central to important problems such as speech recognition and machine translation and instrumental in many other settings. In simple terms, the goal is, given a sequence of symbols (words or characters), to predict the next symbol (word or character), sometimes more than one. Ever experienced Google’s search query autocomplete? There you go!
It turns out that RNN/LSTM networks by now have a clear edge over n-gram baseline methods when it comes to predicting sequences. Karpathy’s now famous post, The unreasonable effectiveness of recurrent neural networks has given us a glimpse into the power of character-based RNN language models, showcasing their "magic" in generating Shakespeare-like text and beyond - although certain prior techniques are in fact capable of similar magic (to an extent). Still, it as already been shown [7] that RNNs are capable of dramatically better performance, improving the language model perplexity by 2x over prior baselines - even on large one-billion-words datasets. The caveat is expensive computation, but as GPUs keep getting cheaper, that’s a fair trade-off.
This leads us to an interesting discussion on the applications of neural language models, such as Machine Translation, Natural Language Inference and of course Chatbots(!), as well as their limitations - namely the lack of adequate attention and memory mechanism, and the recent attempts to address them. But that is a separate topic, and by now I have likely already exhausted your attention budget for this blog. No biggie, I am about to follow up in a separate post. As for the original question, Do I need Deep Learning for my NLU/NLP problem?, here is a quick rule of thumb:
| For text prediction, a.k.a generative tasks, give Deep Learning a good look. For classification, a.k.a discriminative tasks, your mileage may vary. |
In any case, remember, machine learning is an empirical discipline and no two datasets are alike. So you’ll never know the answer for certain until you try!